
データの品質管理やセキュリティへの懸念からAIを本番環境で活用する企業がまだ少ないなか、今後その推進の鍵となりうるのがデータとAIの一元化、包括的なセキュリティとガバナンス、そしてデータインテリジェンスへの移行です。
本ウェビナーでは、まずデータ+AIの活用を理解する土台としてモダンデータスタックを押さえたうえで、上記3つを推進するDatabricksの取り組みと、そのユースケース、さらには注目スタートアップを「Data + AI Summit 2024」から紹介します。解説を担当するのは日商エレクトロニクスUSA米国駐在員の門馬とSojitz Tech-Innovation(7月より日商エレクトロニクスから商号変更)にてDatabricks社製品のビジネスをリードする藤村です。
データ関連のエコシステム、モダンデータスタック
モダンデータスタックとは、クラウド環境における「データ関連のエコシステム」で、データレイクを中心としてさまざまな機能を提供するスタートアップがAPIなどで連携しながら包括的なデータ基盤を構築しています。主な機能は次のとおりです。
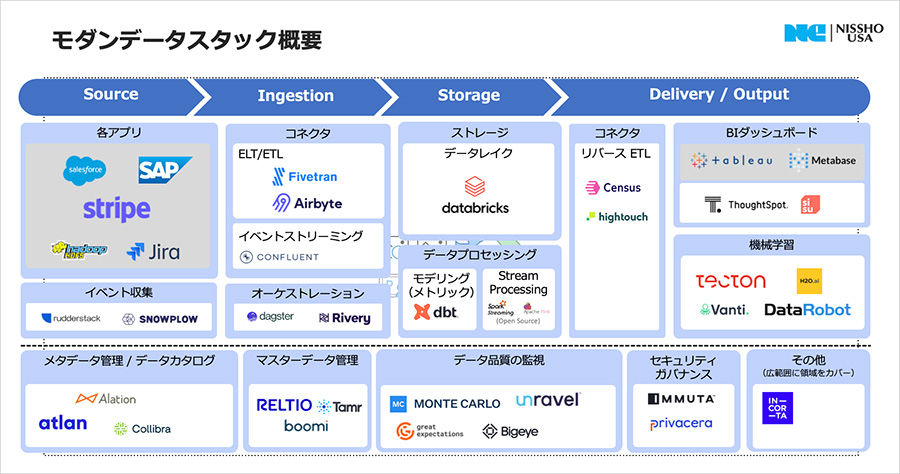
- ELT/ETL:ETLは、さまざまなアプリケーションからデータを取り込むときのExtract(抽出)、Transform(変換)、Load(読み込み)のプロセスを指す。ELTはその順序が変わったもの。データを取り出すまでのアプリ間のコネクタを担う
- イベント収集:サイト訪問者の行動データなどを集めて分析する
- データプロセッシング:格納されたデータをSQLなどの使い慣れた言語で簡単に変換できるようにする
- リバースETL:レイクハウスからデータを抽出し、適切な情報をアプリに配信する。例えば、営業担当者が訪問先の情報を事前にSlackなどで受信するなど
- オーケストレーション:ELT/ETLツールやリバースETL、プロセッシングなどの複数の製品を組み合わせるケースにおいて、ジョブの順序の制御やスケジュール設定を一元的に行う
- ダッシュボード(BIツール):分析を目的としたグラフ化を行う。AIを用いたものが主流。自然言語を用いたチャート作成や管理が可能
- 機械学習:格納されたデータから業務に特化したデータを抜き出す。モデルのトレーニングなどを容易にする
- メタデータ管理・データカタログ:データの場所を整理してカタログ化し、容易にデータにたどり着けるよう
- マスターデータ管理:複数のシステムに保管されたデータを統合し、いわゆる神様データを作成する
- データ品質の監視:データの流れを監視し、異常があった場合にその原因を素早く調査する
- セキュリティガバナンス:法令に準拠して情報を保有できているかをチェックする
ワンプラットフォーム戦略を取るDatabricks社
このエコシステムの中心であるデータレイクを担うのがDatabricks社です。その同社は最近、その他の領域に手を広げた「ワンプラットフォーム戦略」を拡大しています。ここからは2024年6月10日~13日にサンフランシスコで開催された「Data + AI Summit 2024」の内容から、Databricks社の取り組みやユースケース、さらに注目スタートアップを見ていきましょう。
AIの本番利用を大きく推進する3つの取り組み
イベントでは、データ+AIの活用を推進する際の課題として、「複雑化するデータ基盤」「セキュリティとガバナンスへの対応」「データインテリジェンスへの移行」という3点が挙げられました。各課題にDatabricks社がどのように対応しているのか、ひとつずつ解説します。
1. データ活用に必要なすべてを一元化するレイクハウスのアプローチ
データの活用のためのプラットフォームは非常に複雑です。データレイク、データウェアハウス(DWH)の特性を理解し、運用やアウトプットまで設計しなければなりません。またデータはさまざまなフォーマットがあり、それらを適切に組み合わせるのは非常に大変なうえ、コストも増大します。
そうした課題に対して、Databricksはレイクハウスというアプローチを採用し、データ活用に必要なすべてをひとつのプラットフォームで提供しています。言うなればスマホひとつで電話、インターネット、地図、ゲームなどの機能が使えるように、データウェアハウス(DWH)、データガバナンス、データサイエンス・マシンラーニングなどを1か所で利用することが可能です。またMicrosoft Azure、AWS、Google Cloud上のデータを統合し、複製や二重保管を行うことなく、一元的に管理・分析することができるほか、データベース、ログ、テキスト、音声、動画、画像などあらゆる形式をサポートしている点も特徴です。

2.包括的なセキュリティとガバナンスを提供するユニティカタログ
データやAIを活用するうえで、ガバナンスとセキュリティは非常に重要です。適切に実施しなければ、信頼性の低下、機密情報の漏えいや不正利用、データ管理コストの増加、コンプライアンス違反などを引き起こしかねません。こうした事態を防ぐには、データ資産全体をカバーするガバナンスが必要です。
Databricksが提供するユニティカタログは、包括的なガバナンスおよびセキュリティのためのツールをオープンソースで提供しています。データの発見、アクセス制限、データ加工の履歴管理、データの共有、監査、モニタリングなどの機能により、ローデータだけでなく、AIのモデル、データベース、ファイル、ダッシュボードなど、すべてのデータ資産にガバナンスを適用できるため、品質の確保、アクセス権限やポリシーの適用、攻撃からの保護の実現が可能です。
3.自社データをビジネスで活用するためのデータインテリジェンス
自社のデータをビジネスで活用する場合、ChatGPTのような一般的なAIと比べて学習データ量が少ない状況で、AIに自社独自の定義や意味を理解させる必要があります。また自社データをAIで活用するには、開発者が常に高い精度を維持し、有害なレスポンスが発生しないよう制御しなければなりません。
こうした課題へのソリューションとなるのが、Databricksのデータインテリジェンスです。具体的には、データの準備段階で読み込んだデータを自動的にインデックスし、意味を解釈して検索可能にするほか、評価段階でAIモデルの精度を常にモニタリングし、精度が下がった場合にアラートを出すなど、データの準備、ビルド、デプロイ、評価といったプロセスごとに効果を最大化します。さらにAIのみならずBIの部分においても、統合ガバナンスで管理する仕組みを備えています。
ほかにもデータ加工技術や、コラボレーション機能など、データインテリジェンスの実現を支援するさまざまな機能も包括。これらはすべてサーバーレスで提供されるうえ、BIを利用する瞬間やAIモデルを作る瞬間だけの従量課金で利用できるため、コストパフォーマンスにも優れています。
AI+データ活用のユースケース
イベントでは、Databricks社のサービスを活用したさまざまなユースケースも紹介されました。それぞれについて簡単に紹介します。

1.MLBのテキサスレンジャース
昨シーズン63年の歴史の中で初めてワールドシリーズを制覇したテキサスレンジャースは、選手のパフォーマンスやファンとのリレーションシップなどのデータをすべてレイクハウスで一元化しています。バットの振り方から癖を分析したり、捕球姿勢から守備能力を測定したり、打者に合わせて守備位置を修正したりするほか、将来の選手のパフォーマンス理解やスカウティング戦略にも活用。その結果、データ量は4倍になったうえ、データのサイロ化が解消され、試合後の選手へのインサイト提供も10倍速くなりました。
2.ゼネラルモーターズ
以前は毎年200人分の時間をオンプレミスでのデータ収集と分析に費やしていたゼネラルモーターズでは、ほとんど何もないところからクラウド移行に着手。ユニティカタログの活用により短期間のうちにAIシステムを完成させ、約15か月で本番環境を構築しました。Data Insight Factoryと名付けられたこのシステムには、顧客体験、自動車の予知保全、安全性評価につながるデータが蓄積されています。
特に同社が力を入れるパーソナライズされた体験の提供には、顧客ビューの一元化が欠かせません。その実現のために利用していたAmplifies社のCDP(顧客データプラットフォーム)に「Lakehouse CDP」という機能が追加されたおかげで、データをDatabricksと共有できただけなく、ガバナンスの強化にもつながりました。
3.JPモルガン
JPモルガンは世界最大の取引量を処理する金融機関です。そのデータ基盤は非常に複雑で、50以上のシステム接続、ストリーミングやバッチ、APIといったさまざまな形でデータ受信に対応しなければなりません。また利用者のアプリも高度化しており、取引履歴などの迅速なデータ提供だけではなく、予測機能のような、高度な分析も求められています。
そこで同社は、Databricksを活用して大規模なシステムをクラウドに移し、閉鎖的なデータ基盤の利用をよりオープンにするプロジェクトを遂行。結果的に、データを用いたサービスの収益化までの時間を短縮できたほか、データエンジニアやアナリスト、非技術社員のコミュニケーションが活性化し、データの可視性が向上したことで、イノベーションの加速にもつながりました。
4.AT&T
AT&Tが管理するデータには顧客情報や取引情報などが含まれ、その量は1日10ペタバイトにのぼります。そのため、オンプレミスでの運用時は約6~7,000個のCPUコアを使用していたにもかかわらず、すべてのデータを処理してKPIに基づいた分析を行うのになんと32時間もかかっていました。
現在はその多くをクラウドに移し、CPUコア数を1,000個まで削減。膨大なデータ処理を一括で行うのではなく、複数のアプリを多段で構成することで処理スピードを高めたほか、基本的なデータ品質チェックを段階的に行うことで乱雑な情報を少ないリソースでスムーズに取り込めるようになりました。その結果、無駄なデータ処理が30%削減し、分析にかかる時間も8時間にまで短縮。同社はこれらのデータを活用して、顧客への提案強化や不正検知などを実施しています。
注目のスタートアップ5社

1社目:Bigeye(機械学習を用いたデータオブザーバビリティ)
高度な機械学習を用いた異常検知の自動化や、詳細なリネージ(データの起源、移動経路、変換履歴などを追跡するための情報)を提供するスタートアップ。Eコマース、金融サービス、ヘルスケアなどの領域で中小企業のデータチームをターゲットとするものの、実際には製品の完成度の高さからUnion Bank、Unity、Zoomなど大手企業からも利用されています。主なレイクハウスやデータ基盤との連携も可能。
2社目:Prophecy(データパイプライン作成のCopilot)
データパイプラインの開発、実装、管理を行うためのローコード開発プラットフォーム。AIが設定を提案したり、自然言語でQ&Aを行ったりできるコパイロット機能を提供しています。Databricks社製品との連携機能や監視機能が充実し、顧客にはJ&JやVISA、ドイツテレコムなど大企業も。
3社目:Superblocks(カスタムアプリ開発、ローコードプラットフォーム)
UI上でのドラッグアンドドロップの操作を中心に、レイクハウスやチケットシステムを簡単に連携させることができるカスタムアプリ開発プラットフォーム。金融サービス事業者の開発者が利用しやすい機能が充実しています。
4社目:Kumo(グラフニューラルネットワークの簡単な実装)
グラフニューラルネットワークの技術を組み込んだ高精度な予測AIを簡単に実装できるツールを提供。リレーショナルデータを予測AIに変換するプロセスを簡素化し、パーソナライゼーション、詐欺検出、マネーロンダリング防止などに活用されています。スタンフォード大学、ドルトムント大学との共同研究をもとに製品を開発している点が他社との差異化ポイント。
5社目:Unstructured(人間が生成したデータとAIモデルのギャップを埋める)
PDFやPPTXなどの非構造化データをAIが読み取れる形式に自動変換する機能を提供。企業のLLMデータの前処理に対する高い需要を受けて急成長しています。利用者には金融機関や防衛機関も含まれ、2024年1月に開始された有償サービスもすでに1,000社以上が導入。製品の使いやすさと包括的な連携機能が特徴です。
まとめ
今回は、、クラウド環境における「データ関連のエコシステム」、モダンデータスタックを理解したうえで、Databricks社が取る「ワンプラットフォーム戦略」について紹介しました。その戦略の成果は事例として確実に増えており、上で見たようにさまざまな業界の大手が同社の製品を活用しながらデータ+AIの基盤を構築し、生産性向上やコスト削減などを実現しています。各企業は今後これらエコシステムとワンプラットフォームの2つの潮流の動向を注視したうえで、要件にあった実装を行う必要があるでしょう。
最後までお読みいただきありがとうございました。
Nissho USAは、シリコンバレーで35年以上にわたり活動し、米国での最新のDX事例の紹介や、斬新なスタートアップの発掘並びに日本企業とのマッチングサービスを提供しています。紹介した事例を詳しく知りたい方や、スタートアップ企業との協業をご希望の方は、お気軽にお問い合わせください。